Adding data sources
- The data source abstraction
- Collective Data Source
- The DataSource Animator
- Data source collections
- Dynamic data source collections
- Bufferization
- Templates
- File types
- Data source providers
- Feedback and user actions, the ContextualActionProvider interface
- Synchronization between threads
- The event system
- The Listener Manager class
- The DataSource pool
- Serialization
The data source abstraction
Data sources were created to unify the way to bring data to JSynoptic. With this abstraction, it is possible to read an ASCII file, use a socket connection, a binary archive... JSynoptic doesn't ,make any difference between them. Rather, it is up to the plugins to bring in new data and make it available using the DataSource common API.
In JSynoptic, all data sources are index based. That is, they should provide values for given indexes, or throw an exception. Consider for example a time series.
My Data : 2 3 5 7 11 13 17 19 23...
This series could associate prime numbers to index, starting from the first
My Data : 2 3 5 7 11 13 17 19 23... Index : 0 1 2 3 4 5 6 7 8...
This data representation is particularly well suited for parametric curves. In fact, this is how data are plotted on standard plots : the first index of the Y source is matched with the first for ,the Y source, then the second, and so on, so as to make (X,Y) couples of values. The couples are then connected with lines to draw the curves.
It is very important to understand this if you are to bring in new data sources to JSynoptic. The data source API reflects this paradigm. And if for some reason your data source is not able to provide data for an index, you can either choose to return a null value, meaning no data is available but this is normal, or throw an ,exception if the index is out of your index range for example. You can even return not-a-number values. String values, for example, willbe correctly interpreted by the text shapes, but of course won't plot anything when used in a graph.
For optimization purposes, data sources can also have a type. Thisis not mandatory, though. All data conversions are done internally byJSynoptic to provide the data in the type really needed by theobjects that displays them. Text shapes will convert numbers toStrings for example, and will do so in a way parameterizable by theuser in the shape properties dialog. On the other hand, data plotswill use double values. Thus, if you provide a data source of theDoubleProvider kind, the plots would read directly the data withoutconversion. This is also quite important for buffered data sources, as in this case the buffer could internally storethe data in a much more efficient manner.
Data also have meta-information. The most obvious one is a name,also called label. This name is mandatory, all data sources have aname. They also have an ID. The ID meaning is only relevant to thedata source creator, but should be enough to uniquely identify itfrom other data sources. Data sources can also have an alias, a unit,a comment, and be linked to other data sources. See the DataInfoclass in the simtools.data package for all possible meta-informationon data sources.
You can implement data sources by extending the DataSource class, in the simtools.data package. You'll find basic examples in this samepackage, in the jsynoptic.builtin package, and in the src/examplessubdirectories.

|
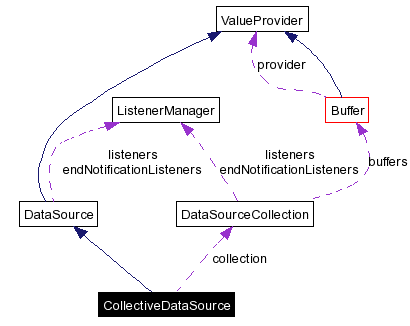
DataSource is an abstract class which extends ValueProvider. If your data source is asynchronous, you may exend TimeStampedDataSource Otherwise you can use a collective data source which depends on a collection data source collection, or directly extend DataSource class for some specific needs. |
CollectiveDataSource
These are in fact delegates for the collections. A data source collection handles all value operations by itself, so it uses data source with delegated methods back to itself.
On the other hand, collective data sources may be bufferized individually. This adds an additional complexity which can only be handled at the data source collection level. This is the reason why the DataSourceCollection handles directly the buffers in the diagram below.
Take for example the case where a collection reads its values from a multicolumn ASCII file. In this case, each column corresponds to a data source. But the file is read line by line, each line leading to a new index. Thus, it would be completely inefficient to read the file as many times as there are data sources. Rather, it is much more efficient to fill the buffers for all collective sources at the same time when reading a new line. This way, when data is needed from another collective source, the value may already be present and there is no need to read the line again.
DataSourceAnimator
This class was specially designed to wrap a DataSource and make a dynamic version of it.
It basically uses the DataSource by reading its elements one by one, and feed them to the DynamicDataSource API.
It is API programmable to start/stop automatic production with a given frequency, step by step advance in index, and reset to the first index.
JSynoptic extends it to add Actions for this API, thus making user controls for each of those actions.
Data source collections
When data sources share a lot in common, it is possible to gatherthem in a data source collection. Those are the “folders” thatappear in the left panel of JSynoptic.
In particular, data source collections should generally ensure thedata source they contain have compatible index. Let's take anexample. An ASCII file has columns of values, and one new data sampleper line. This makes it a clear candidate for a data sourcecollection : since the file is read line per line, obviously the datasources corresponding to the columns have matching index for data onthe same line. Also, in this case, there is a clear logical linkbetween the data sources (they come from the same file). Thissituation also holds for data coming from the same packet on asocket, for example.
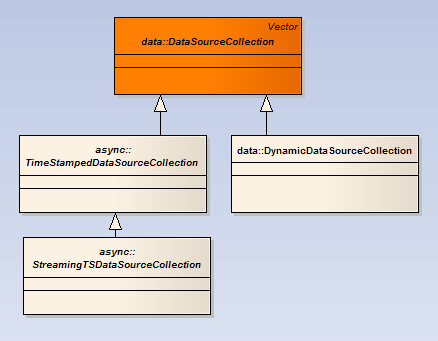
The data source collections are compatible with Java collections,as they are in fact subclasses of Java Vector.
You can implement data source collections by extending theDataSourceCollection class, in the simtools.data package. You'll findbasic examples in the jsynoptic.builtin package, and in thesrc/examples subdirectories.
|
DataSourceCollection is an abstract class which extends Vector. If your data sources are asynchronous, you may exend TimeStampedDataSourceCollection If your data sources are dynamically updtated they can be gathered into a DynamicDataSourceCollection. Otherwise you can directly extend DataSourceCollection class for your specific needs. |
Dynamic data source collections
In JSynoptic, dynamic data sources are represented with green icons showing a triangle like Play on a remote control.
But what is dynamic data?
In fact, all data is considered dynamic. Two helper classes,DynamicDataSource and DynamicDataSourceCollection, are what make theicon change, as previously mentioned.
When a JSynoptic data source is loaded, all objects using itregister themselves as listeners. The data source then emitsnotification when its index, value, or information state changes.Interested listeners may then choose to ignore or re-configurethemselves accordingly.
So, when implementing a new data source, please take care of calling the listeners when your data source state changes.
As an example, let's consider extending theDynamicDataSourceCollection helper class. All you have to do iscalling createDataSource(...) with the relevant data information(name...), for each source. Then, when new data arrives, use thesetValue() related methods to indicate it to the system. Finally,when all data source are OK, call registerNewValues(). This will inturn take in account all the values set, create a new index, and callall the listeners for you. Note that once you have registered thevalues (but before setting new ones) you can once again add or removedata sources.
The DynamicDataSource class is even simpler. Call setTypeValuewhen some data arrives, where Type is the type of the data source asdeclared in the DynamicDataSourceconstructor. If auto-registering is on, events are sent to notify listeners that thisdata source has changed. Otherwise, call registerNewValueasabove.
In each case, bufferization is handled either by specifying adelay in the constructor, or by calling the bufferizemethodlater on.
Bufferization
Bufferizing data sources has 2 objectives:
- For static sources, it increases the performance of the application by reducing the number of calls to the buffered data source getValue().
- For dynamic sources, it keeps past values in memory, thus allowing to display them.
To bufferize a data source, wrap it into the buffer class of yourchoice. Simple buffers are fixed-size buffers, with a simple policyto discard elements when the buffer is full. Resizeable buffers arelike the simple buffrs, but will grow up to a maximum size beforediscarding elements. Delayed buffers are specially crafted fordynamic sources, and are the only buffer that should be used withthem.
Additionally, helper class methods are provided in theDataSourceCollection to bufferize one or more data sources. Pleaseuse them instead of manually wrapping the sources, as these methodssolve non-obvious problems related to data source collections. Forexample, ASCII data files are read line by line, so each buffereddata can benefit from the reading.
At present, it is not possible to modify a buffer once set.
Templates
Data source templates appear in the source generator of JSynoptic.They act as a data source factory of a given type. Usually, the userenters some parameters, and then a data source of the chosen type iscreated with these parameters. For example, the builtin plugin ofJSynoptic provides a template for making random sources taken from aGaussian distribution. The user enters the mean and varianceparameters (among others), and a Gaussian source is createdaccordingly.
Templates are fully integrated in the plugin API. Just return anon-empty string array of the template names you offer by overloadingthe getSources() method in your plugin. Then, when the user creates adata source from this template, the system calls your plugincreateSource(...) method. It's up to your plugin to propose dialogboxes, etc... for any parameter you may require for creating a sourceof this type. All the system expects is that a valid data source isreturned from this plugin method.
See also the builtin plugin as a good example of how to use sourcetemplates.
File types
As for templates, a plugin can also manage different file types.For example, the builtin plugin manages the files of type “.syn”and also ASCII files.
Now, suppose you create a plugin to read the .foo files,containing data of the utmost importance. The plugin has to override the getFileFilters() method to provide file filters able to recognize the .foo files. Then, when the user opens (or save) data in the.foo format, the plugin processFile(...) method is calledaccordingly.
What is done in the processFile is at the plugin discretion. Youc ould, in this example, open the .foo file and add a new datasource collection to the systems. A real-time plugin could open a CORBA connection from the information in the opened file, then display a dialog box to show the naming service, and finally create adata source or collection listening on a socket receiving data from a selected CORBA object (yes, this was really done).
Alternatively, you could export the currently displayed synoptic in another format, or whatever you wish.
See the builtin plugin for an example of how to manage new fileformats.
Serialization and data source providers
Serialization is used when saving a synoptic. Only the synoptic parameters are saved, together with the layout. The data used in the plots and other shapes is not saved in the synoptic file.
Instead, pointers to the data sources used in the shapes are saved. Think about dynamic data, for example a socket connection. It makes no sense to record all current data. Rather, it makes sense tosave the connection parameters and propose the user to re-open theconnection when loading the synoptic. Even for static data, it isn't a good idea to save the data in the synoptic, which would actuallyduplicate the content of the original data file.
Moreover, synoptics are often used as templates to comparedifferent data files. Just load the synoptic and choose another datafile defining the same sources, and you get the same presentation asbefore but for the new sources. For example, a student in a computerlab could easily compare all the computations results from differentmodels using the same parameters.
So, when a plugin defines a data source, it should also define acorresponding data source provider. This provider's goal is to manageto parameters which are saved in the synoptic file, and which allowto reload the source later on.
For example, a provider for a data source read from a file couldstore the name of that file. Then, when reloading the synoptic, theprovider could propose to the user to re-open the same file, orchoose another one.
Providers can be any object implementing the DataSourceProviderinterface (simtools.data package). Good candidates are the pluginitself, the data source collection for you data type, or a separateobject.
Two methods must be overloaded from the interface:
- getOptionlInformation
This ist he method called when the synoptic is serialized. The arguments arethe data source ID for which the parameters are desired, and if applicable the data source collection ID this source belongs to. Aprovider shall always return null for data source ID it doesn'tmanage. That is, only return the parameters for the data source this provider is responsible for.
The returned object will be serialized as is in the synoptic file. It is theprovider's responsibility to ensure this object is indeedserializable. Tip: return an array, or a vector, and thus save multiple parameters.
- provide
This method is calledwhen restoring a Synotic from an serialized file. The provider isasked if it can provide a data source for the given ID, and datasource collection ID if applicable. The provider shall return null if it doesn't manage data sources with this ID.
Another argument is the data source pool in which to put the data source.This argument may be null, in which case the provider should justreturn the data source it creates. If this argument is not null, thenthe provider shall add the source (and/or collection) to the given data source pool (see the DataSourcePool JavaDoc).
Ofcourse, there is another argument : whatever object was given by theprovider at save time (returned from the getOptionalInformationmethod). Use this object to restore the data source (open a connection, read a file, etc).
Tip: Aprovider can return a collection with a different ID than the IDpassed as argument. If so, this association will be kept in memory,and subsequent data sources from the original collection ID willfirst be looked in the second ID. This is especially useful if, forexample, the collection ID is based on a file/host name, and thisparameter is changed by the user at load time. Instead of asking thenew file/host for each source in the collection, it is possible to ask it only for the first source that is re-loaded.
See the various examples in the source/example directory, and the builtin plugin, for practical implementations.

|
The provider interface and some of its subclasses |
Feedback and user actions, the ContextualActionProvider interface
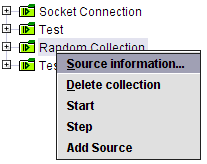
In the left panel of JSynoptic, it is possible to right-click on sources or collections and a popup menu appears. This menu containsentries depending on the selected object. For example, the ASCIIfiles opened as dynamic sources have an option to start or stop reading values. The examples in the src/examplessubdirectories have other entries, including an add source option in the random source plugin.
|
It is possible to right-click on sources or collections and a popup menu appears |
It is very simple to add such entries in the menu : just make your data source or collection objects extend the ContextualActionProviderinterface (in the jsynoptic.base package).
This interface contains three methods:
- getActions
The context is passed as argument to the method (for data sources or collections, thisshould always be SOURCELIST_CONTEXT). Return the name of the menuentries as a String array in this method. Of course, you can returndifferent arrays for different states of the plugin. For example, the random plugin only proposes to remove a source if one was previously added, and when the animation is paused.
- doAction
This method is calledwhen the user selected an entry previously returned by getActions,and with the same context. It is up to the plugin to interpret this action as it sees fit. This method may return false if for any reason the action failed, though this indication isn't used at the moment.
- canDoAction
This is called shortly before an action is about to be done. This method only has anindicative value, as no synchronization is done between threads.Thus, by the time the method returns, the plugin state may havechanged. On the other hand, if false is returned and the pluginbecomes ready in this short interval, then the action will still notbe processed. The advice here is to return always true, as this function has little significance and may be removed in the future.
About synchronization between threads
In Java, the graphical events are processed in a separate thread.Please refer to the SwingUtilities class in the Java documentation,and especially the invokeLater static method, to prevent unexpectedbehaviors.
For example, when processing an action with theContextualActionProvider interface, as seen above, chances are thecurrent thread is precisely this event thread (because the method iscalled from an event handler for a popup menu). Thus, you shouldensure that the action in question doesn't hang the program or lockan object waked by another thread, to name a few potential problems.
The same is also true for data coming from a socket connection.Usually a thread is created to manage the socket eventsasynchronously. Thus, when calling registerNewValues in a dynamicdata collection (for example), all the listeners will be called fromwithin this thread. Care was taken in JSynoptic for processing thenotification events quite fast, and delaying the graphical refreshesto the Java event thread at a much more reasonable pace not to hogthe CPU (but this may not be enough, seesimtools.shapes.AbstractShape for more details). Of course, if theplugin or a user-defined object also registers as listener, you're onyour own.
Data Source have optional information, like a sorted order, and acomparable indicator. If all values returned by the source arecomparable with each other, then it is a good idea to overload thecorresponding method (isComparable in the DataSource class). Thiswill increase performances slightly. Also, if the data source returnsvalues in a sorted order, please overload the sortedOrder method ofthe DataSource class, as this can lead to important optimizations.
Data sources are shared between the graphical objects. It is notnecessary to make them cloneable. On the other hand, keep this inmind, as changing some data source information affects all objects.
The event system
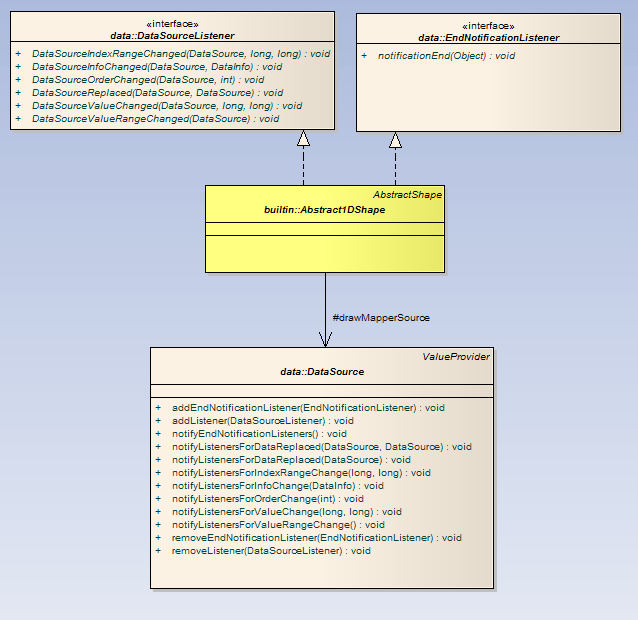
Listeners and end-notification listeners
Each event produced by a data source is notified to all registered listeners on this data source. For example, if the data source last index changes (because data is received from the network, or the file has changed on disk, or whatever...), then an Index Range Change event is generated.
|
A shape have to implement a DataSourceListener to receive notifications from a data source. |
Unfortunately, this leads to an overhead in the number of events generated. In the preceding example, the data range may have changed too, and a second event would then be generated. If the listener does heavy processing on each event received, it might have been more efficient to wait for both events to come before doing the processing. But how to know there won't be more events to come?
Worse, for objects listening on several data sources, the order of received events may be important. For example, changing a color for the current index before changing the current index itself, or the reverse, lead to different results.
In order to accommodate for all these problems and increase performances, a new event has been introduced : the end-notification event.
Thus, a listener on several data sources may register an end-notification callback, and delay its heavy processing to it. All events will be generated as before (in unknown order), but only one end-notification will be sent at the end of all related events (generated from the same object, source or collection). It is enough to take notice in usual events (position a boolean flag or whatever) that the event occurred. Then, in the end-notification callback, it is possible to order all received notices and take action accordingly.
For example, if new data arrives on the network for a data source collection, and your shape listens on several data sources, you will find it more efficient to wait till all data sources send their index range changed, value range changed or data info changed, and update only once to take in account all these.
As an implementation example, please refer to the Shapes in the Builtin plugin. The Text Array shape, for example, waits on many data sources, but updates its appearance only when necessary.
On which thread are run listener callbacks ?
Listener callbacks run in the calling thread which is not necessarily the same thread as other methods of your object usually run in.
Synchronization may thus be necessary. In the previous example, the callbacks would be called probably from a socket-management thread. This is especially important when interacting with Swing objects. Please use the as other methods of your object usually run in. Synchronization may thus be necessary. In the previous example, the callbacks would be called probably from a socket-management thread.
This is especially important when interacting with Swing objects. Please use the SwingUtilities class from the JDK, and especially its invokeLater method, to perform updates to the graphical part of your object from within a callback. invokeAndWait is a bad idea as this would block the event system for all other listeners.
The Listener Manager class
The listener manager class in the simtools.utils package was created to solve several problems, and avoid code duplication Please use it in as many place as possible.
Its goal is to provide a listener list usingreference counted pointers, so that multiple listener registration still results in only one notification, and there is no memory leak.
When an object registered as listenerbecomes unused, the fact that the listener list holds a reference toit prevents it from being freed by the garbage collector. This endsup in objects not being freed, and growing listener lists of unused objects.
This is bad, and listener lists are a very common source of memory leak! Beware!
>A naive and developer-unfriendly approach would be to tell all registering objects to unregister before theyare unused... This is easy to do in C++ where there are properdestructors, but in Java the finalize() method is precisely called bythe garbage collector, which won't call it in the present case since the listener list still holds a reference. Back to the beginning.
An even-more developer-unfriendly approachwould impose a constraint on all objects using objects registered aslisteners to do the cleanup, but this is a real mess and does noteven work for other reasons (for example, think of inner classesregistering private members as listeners, or other awful cases wherethe object using another object using another object using... has noway of unregistering a listener without modifying drastically the API just for that). doc++
>Weak references were introduced in Java 1.2to solve this problem. If only weak references to an object remains,the garbage collector discards it. The get() method of the weakreference holder then returns null. A queue (waiting thread) can beused to be notified when this happens, as the application does notdecides when the object is finalized (this is handled by the garbage collector thread).
On the other hand, weak reference pointersmay become invalid any time! And for JSynoptic, we have an additionalproblem : The same object may be registered as listener severaltimes, but should be notified only once. See the EndNotificationListener class for a concrete example of this.
Thus, a Set is not adapted to hold only onereference of each listener. If an object is registered twice by twodifferent paths and unregistered only once, it is still expected tobe notified by the second registering path. Hence, it must still bepresent in the listener list, which would not be the case using a Set.
The solution is of course referencecounting, which is applied on the register/unregister operation. Thisis complementary to the WeakReference mechanism : if an objectforgets to unregister or doesn't have the occasion to do so beforebeing thrown away, then the weak reference mechanism will stilldiscard it even if the refcount field is >1, which is what wewant. On the other hand, if the refcount field goes down to 0, theobject is removed from the listener list, but this does notnecessarily mean the listener is unused. It may just haveunregistered and live its life as usual. As in this case the listenerlist does not hold any reference to the object, it cannot be the source for a memory leak.
So, the refcount field is notrelated to the weak reference mechanism. It is necessary for another reason entirely, as described above.
Another source of fun comes from the factthat the listener manager itself is referred by the weak referencecounted pointers. Indeed, the Weak reference mechanism introduced inJava makes use of a helper thread notified by the garbage collectorwhen a referenced object is destroyed, as previously said. In orderto keep performances at a reasonable level, it is not reasonable todeclare one such thread per listener manager. Thus, only one threadis declared, and a weak reference to the listener manager it refersto is introduced in each reference counted weak pointer. With this, it is possible to decrease the refcount properly.
The result of all this is a clean, fast wayto avoid the memory leak problems plaguing naive listener implementations.
Warning : It is necessary to use externalsynchronization on the manager before using the size() and get(int)methods, as otherwise the size may vary according to the whims of thegarbage collector. The synchronized block should surround both the size() and get(int) calls. See for example the code in the DataSource class.
The DataSource pool
This abstraction is responsible for handling all sources for the application. It is possible to declare and use more than one data source pool, but not recommended. In particular, this would lead to two distinct Source Tree, and potential duplicates on data de-serialization. But if you precisely wanted two source trees, this is the way to go. Be aware, though that the static “global” field in the DataSourcePool class is used in several places and building two data pools was not tested. The feature is implemented, though, and it may even actually work !
Serialization
One of the added values of the data source pool is to handle the serialization for data sources.
Indeed, the DataSource objects are not Serializeable. This is intentional and expected, as some data has transient nature (ex: network stream) and should not be stored by simtools (use a network traffic logger for that). Anyway, the data package is just an abstraction that takes in account many aspects of data handling, and is not designed as a data producer itself (notwithstanding example data sources). Finally, when reading data from a file, there is no point in duplicating that file.
Still, in itself, this would not be enough to delegate the data source serialization to the pool (and rather, the serialization could be done directly in the DataSource class). So, why is the delegation necessary?
Data sources may depend on each other. In the obvious case of data source collections, the same argument as above is still valid, so collections are not the reason either. Things get more complicated with data source animators, but even then, the situation could be handled completely locally.
So, the reason why the pool handles serialization is that when a data is saved and restored, it instead saves and restores references to what allows to re-create the object (whether the references are a server/port address, a file name, a CORBA IOR of a server object, or whatever, this is still conceptually a reference). And references might change.
Take for example the case where the user saves a data source that was created by loading file A. The reference to file A will be saved (path, file name, type...). But on reload, the user might very well decide to load file B instead, with the same format. Or file A may simply have disappeared. In this case, the reference associated to the data source has changed, but the role of the data source in the application is still the same. That is, wherever file A was used previously, file B is now used, but the data source object is exactly used in the same way.
The data source pool maintains a translation table of object reference mappings. This is quite complicated stuff, and out of the scope of this manual (please read the code comments). The main point to know is that as far as the rest of the application is concerned, the change has no impact. This would not be the case if the data source handled their serialization directly, at least not without an external mapping. The example above could not be done because the data source may not be the single one the the file, and if the file changed too much, it may be necessary to create several additional collections to cover for all previous sources. For this reason (and others, read the source comments), all data source serializations are managed by the source pool, which can then do what is necessary to ensure the data sources and collections are saved and restored correctly.